
Headless WordPress: REST or GraphQL

Hey 👋🏻 !
I'm Kevin, a full-stack developer running a digital prototyping company with my business partner called Spin Up.
When I'm not consulting and building for clients, I'm writing content here, curating my newsletter or creating videos.
Outside of work, I enjoy handing out with my wife and sons - camping, hiking and kayaking or just curling up with a good book.
One of the strengths of using WordPress as your content backend is that you have a lot of choice. You can decide where to host your instance, how to organise your content types and how many different users and roles you want to introduce.
I don't know if it is unique but I find it pretty cool that you can interact with the API in multiple ways also.
Fancy dealing with a RESTful API? Fine! We've got that out of the box. Want to carry out multiple calls or would you rather extend the API to meet your exact needs? Up to you!
Are you a graphQL afficianado? Do you love posting those queries, asking for the exact shape of data you want and getting just what you asked for? Well, we've got you set up there too!
REST API
The base install of WP comes with a great self-documented RESTful API available at /wp-json. With no extra configuration, you can get access to your posts, pages, users and comments straight from your API client.
This is pretty cool. Like all RESTful clients that are designed for more than one purpose, there are some problems. Almost always, you'll get more data than you need or you'll need to carry out multiple call to get the data you want.
Look at a typical blogpost built with WP.
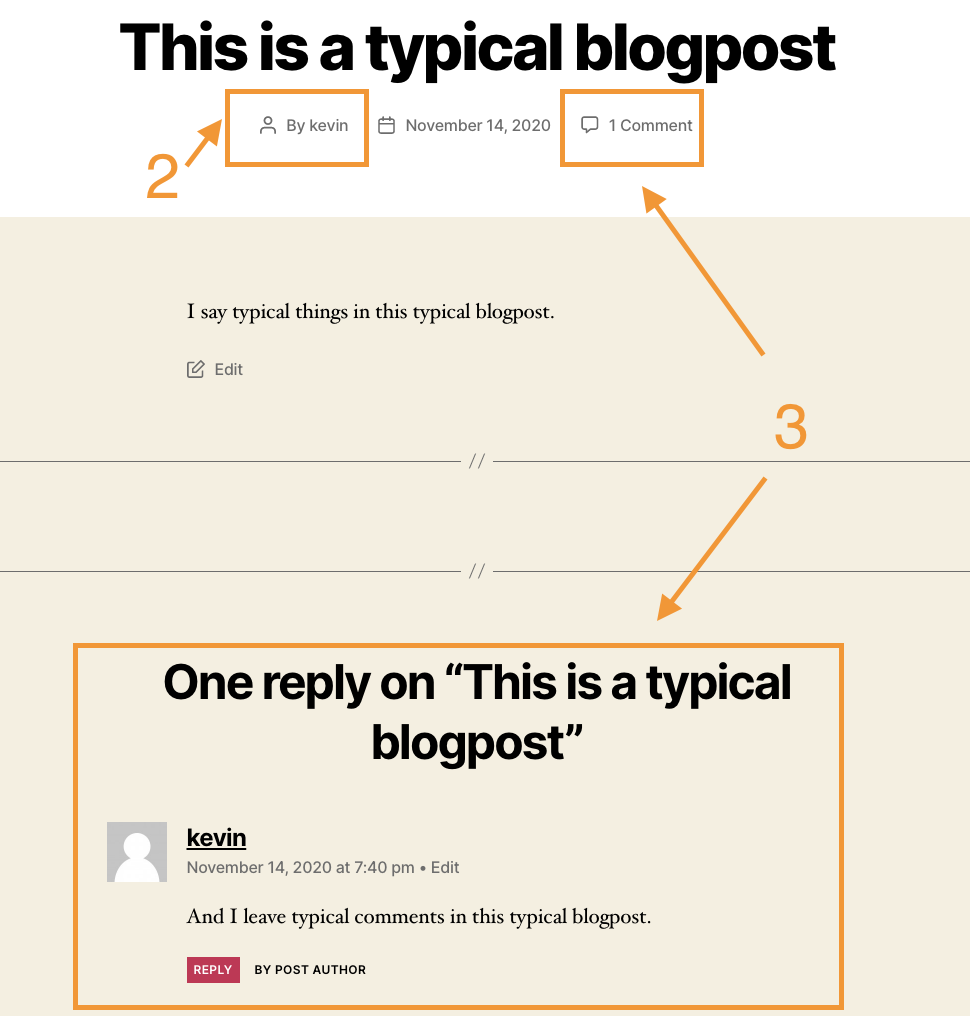
In a typical WordPress install, all of the data for this page is retrieved from the database, combined, rendered and then sent to the user. In a Headless world, if you want to construct this same page, you'll need to make 3 separate calls.
The first call will get the post data. We'll get the post data including the title, date and the rendered content. In this call though, our author will be represented by their user id.
{
...
"author": 1,
...
}
So, we need to make another call to be able to get the user details for this author. Helpfully, the original call includes the endpoint for this.
{
...
"author": [
{
"embeddable": true,
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/users\/1"
}
],
...
}
The forward-slashes (/) are being escaped, so this looks a little strange. Without the escapes, this is equivalent to http://headlessegghead.local/wp-json/wp/v2/users/1. Calling that endpoint gets me the author details that I can use to create my page.
{
"id": 1,
"name": "kevin",
"url": "http:\/\/headlessegghead.local",
"description": "",
"link": "http:\/\/headlessegghead.local\/author\/kevin\/",
"slug": "kevin",
"avatar_urls": {
"24": "http:\/\/0.gravatar.com\/avatar\/c2b06ae950033b392998ada50767b50e?s=24&d=mm&r=g",
"48": "http:\/\/0.gravatar.com\/avatar\/c2b06ae950033b392998ada50767b50e?s=48&d=mm&r=g",
"96": "http:\/\/0.gravatar.com\/avatar\/c2b06ae950033b392998ada50767b50e?s=96&d=mm&r=g"
},
"meta": [],
"acf": [],
"_links": {
"self": [
{
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/users\/1"
}
],
"collection": [
{
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/users"
}
]
}
}
The last piece of data we need to recreate the original post is the comments. Helpfully, the endpoint for this is also in the original call.
{
...
"replies": [
{
"embeddable": true,
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/comments?post=39"
}
],
...
}
Again this URL is escaped and so becomes http://headlessegghead.local/wp-json/wp/v2/comments?post=39. Calling that URL gives us,
[
{
"id": 4,
"post": 39,
"parent": 0,
"author": 1,
"author_name": "kevin",
"author_url": "http:\/\/headlessegghead.local",
"date": "2020-11-14T19:40:57",
"date_gmt": "2020-11-14T19:40:57",
"content": {
"rendered": "<p>And I leave typical comments in this typical blogpost.<\/p>\n"
},
"link": "http:\/\/headlessegghead.local\/this-is-a-typical-blogpost\/#comment-4",
"status": "approved",
"type": "comment",
"author_avatar_urls": {
"24": "http:\/\/0.gravatar.com\/avatar\/c2b06ae950033b392998ada50767b50e?s=24&d=mm&r=g",
"48": "http:\/\/0.gravatar.com\/avatar\/c2b06ae950033b392998ada50767b50e?s=48&d=mm&r=g",
"96": "http:\/\/0.gravatar.com\/avatar\/c2b06ae950033b392998ada50767b50e?s=96&d=mm&r=g"
},
"meta": [],
"acf": [],
"_links": {
"self": [
{
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/comments\/4"
}
],
"collection": [
{
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/comments"
}
],
"author": [
{
"embeddable": true,
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/users\/1"
}
],
"up": [
{
"embeddable": true,
"post_type": "post",
"href": "http:\/\/headlessegghead.local\/wp-json\/wp\/v2\/posts\/39"
}
]
}
}
]
This gives us an array of all the comments and their authors. We now have all the data we need to reconstruct our original page.
Modifying the API
Rather than making those three calls, we can modify the API to add the details we need on the first call. To do this, we use the WP ecosystem. When the REST API is initialised, we need to add those two new fields.
Let's add the comments first.
add_action('rest_api_init', function() {
// We declare that we want to attach a new field to the
// post object and that we can to call it comments.
register_rest_field('post', 'comments', [
// This is the callback that will be called when we GET
// on this route.
'get_callback' => function($post_arr) {
// We extract the post_id from the post array.
$args = [
'post_id' => $post_arr['id']
];
// Use that argument to get the comments,
$comments = get_comments($args);
// And return as an array.
return (array) $comments;
},
// Here we describe the schema of the field.
'schema' => [
'description' => __('Comments'),
'type' => 'array'
]
]);
});
There is a lot going on there! I've commented the code pretty extensively. We're adding a new field, collecting the data and attaching it to the field.
Now, let's get and attach the author details. We can't use author because that already exists.
add_action('rest_api_init', function() {
register_rest_field('post', 'author_details', [
'get_callback' => function($post_arr) {
$author = get_user_by('id', $post_arr['author']);
return (array) $author;
},
'schema' => [
'description' => __('Author Details'),
'type' => 'array'
]
]);
});
Now, when we call the on the post route - the comments and the author details arrive with that single call.
How about graphQL?
If we want to do the same thing with graphQL, we need to do a little bit more configuration.
First, we need to install a plugin that is going to establish and configure a graphQL endpoint. The plugin I use for this is called WP GraphQL. I've just seen that it is available on the WordPress Directory now but up to now I've been installing from the repo.
Once the plugin is installed and activated, we need to query the data from the graphQL endpoint.
query {
posts {
nodes {
title
content
author {
node {
name
}
}
comments {
nodes {
author {
node {
name
}
}
content
}
}
}
}
}
With this single call, we get all of the data we need for the post in a single call without overfetching.
Conclusion
Whichever way you decide to go, REST or graphQL, WordPress has your back. To get the best out of the platform, you need to carry out a bit of configuration.
I've been working on a video course covers this area and all the others when setting up a Headless WordPress instance. If you want to make sure you hear about it, make sure you sign up to mailing list below.



